[컴퓨터 구조]제 2장. 명령어(Instruction) : 컴퓨터의 언어
Instruction
Instruction (명령어)
- Instruction은 processor(CPU)의 작동을 설명하는 가장 basic command입니다.
- 컴퓨터에게 일을 시키는 단위로, 기계어로 이루어진 명령입니다. (컴퓨터의 언어)
- 즉 하드웨어와 소프트웨어의 interfacing(인터페이싱)을 담당합니다.
Instruction은 Opcode와 Operands로 이루어져 있습니다.
- Opcode (i.e., operation code) : 하드웨어가 어떤 작업을 할 지에 대한 명령어
-Operands : 하드웨어가 어떤 대상에 대해 작업을 할지에 대한 명령

add $2, $4, $2가 있을 때, add는 opcode가 되고 $2 $4 $2는 operand가 됩니다.
이것을 이진수로 나타내었을 땐 000000000001이 opcode가 되고 01010100100001010000이 operand가 됩니다.
Instruction set architecture (ISA)
- ISA는 프로세서는 명령어의 집합체로써 (set of instructions) software에서 hardware로 넘어가는 단계에서 중재자 역할을 해준다.
- Machine Language Program을 작성하기 위해 필요한 모든 정보를 말하며 단순히 Instructions의 집합뿐만 아니라 register, memory, access 등을 포함한 모든 정보를 일컫는다.
- 다른 프로세서(CPU)는 다 다른 ISA를 가지고 있지만 매우 비슷합니다. (사투리 같은 느낌)
→ 비슷한 이론에 기반을 둔 비슷한 하드웨어 기술
→ 컴퓨터들이 반드시 제공해야 하는 공통적이고 기본적인 operation(add..)이 있습니다.
ISA는 ARM의 ARMv7, ARMv8이나 Intel의 x86, IA-64 그리고 MIPS 같이 많은 종류가 있는데
수업에선 RISC-V를 선택하였습니다.
Microarchitecture
- microarchitecture는 ISA를 설계 제약 및 목표아래 ISA를 물리적으로 구현하는 방법입니다.
- 하드웨어의 운영에 대해 세세하게 기술이 되어 있습니다.
실제로 같은 ISA를 사용하지만, microarchitecture은 전혀 다른 경우가 있습니다.
같은 ISA를 구현한다 해도 파이프라인의, 캐시 등등 다양한 요소에 차이을 두어서 다양한 프로세서를 만들 수 있습니다.
microarchitecture는 소프트웨어에게 노출되지 않고 수행할 수 있는 것들이 있습니다.
- PipeLining
- Speculative execution (추측 실행)
- Memory Access Scheduling
- Arithmetic units
CISC vs RISC
Cisc (Complex Instruction Set Computer)
- 복잡하고 명령어의 길이가 가변적이다.
- 다양한 명령어들을 포함하고 있어 일반적으로 우리가 사용하는 범용 컴퓨터(general-purpose computer)의 CPU로 많이 사용된다.
- → (x86, 인텔 8080, 모토로라 68000 등등)
장점
- 복합적이고 기능이 많기 때문에 하위 호환성이 좋다. 즉 복잡한 명령어를 이미 하드웨어 수준에서 구현해 두었기 때문에, 어셈블리어 프로그래밍이 쉽다. 따라서 컴파일러가 단순하다.
- 또한 명령어가 비교적 간단하게 끝날 수 있으므로, instruction memory의 사용량이 감소한다. (메모리 접근 횟수를 줄일 수 있다.)
단점
- 하지만 각종 명령어를 하드웨어 수준에서 구현해야 하기 때문에 CPU design이 어렵다.
Risc (Reduced Instruction Set Computer)
- CISC보다 더욱 새로운 개념이다.
- 간단하고, 표준화된 instructions(명령어들).
- 1 Cycle에 1 instruction을 수행하는 것을 원칙으로 한다.(CISC는 복잡한 작업에 몇몇 cycle을 더 사용하기도 한다.)
장점
- CPU를 구현하기 쉽다.
- 더 적은수의 명령어들로 구성되어 CISC보다 더 빠른 속도로 동작할 수 있으며, 단순하고, 전력 소모가 적고, 가격도 저렴하다.
단점
- 어셈블리어 언어가 대체적으로 길다. 따라서 instruction이 많아지기 때문에 메모리 사용량이 증가할 수 있다.
- 하지만 하드웨어가 간단한 대신 소프트웨어가 크고 복잡해졌으며, 하위 호환성이 부족하다.
→ 즉 간단한 작업도 하드웨어는 단순한 명령만 처리하기 때문에, 소프트웨어가 이를 처리해야 한다.
• RISC 구조는 파이프라인 중첩이 가능해서 같은 수의 명령어에 대해 적은 clock으로 처리가 가능하며 발열과 전력 소모도 줄일 수 있다. 따라서 임베디드 프로세서에서는 RISC 구조를 많이 사용한다. (MIPS, ARM)
RISC-V
Design Principle 1 : Simplicity favors regularity.
add a,b,c
RISC-V의 모든 산술적인 명령어는 이런 형태를 가지고 있습니다.
모든 산술 명령어는 3개의 변수를 가지고 있으며 2개의 source 1개의 destination으로 이루어져 있습니다.
예를 들어, 4개의 변수 b, c, d, e의 합을 a에 넣고 싶다면 3개의 instruction이 필요합니다.
add a, b, c //a=b+c
add a, a, d //a=a+d
add a, a, e //a=a+e
Design Principle 1 : Simplicity favors regularity.
- Regularity는 구현을 간단하게 만듭니다.
- Simplicity는 더 적은 비용으로 높은 성능을 가능케 합니다.
ex)
f = (g + h) - (i + j);를 계산할 때
add t0, g, h // t0 = g + h
add t1, i, j // t1 = i + j
sub f, t0, t1 // f = t0 - t1
산술 instructions는 register operand를 사용한다.
(레지스터를 연산처리기로 사용한다는 뜻)
RISC-V는 32-bit 레지스터를 32개 가지고 있다 : x0~x31
- 자주 접근하는 데이터를 위한 고속의 저장소
- 32-bit 데이터는 word라고 한다.
- 64-bit 데이터는 doubleword라고 한다.
Design Principle 2 : Smaller is Faster.
- 많은 수의 레지스터는 clock cycle을 늘립니다.
→ 이는 곧 속도의 저하를 의미.
- 따라서 성능과 레지스터 관계는 trade-off 합니다.
하지만 위의 Principle2 가 절대적인 것은 아닌 게 31개의 레지스터가 32개의 레지스터보다 빠른 것은 아닙니다.
Memory Operands
메인 메모리는 arrays나 structures 같은 Composite data(복잡한 데이터)에 사용합니다.
- 배열의 원소는 register에 저장 x
- 레지스터는 32개로 제한되어 있으므로 Composite data를 수용하지 못합니다.
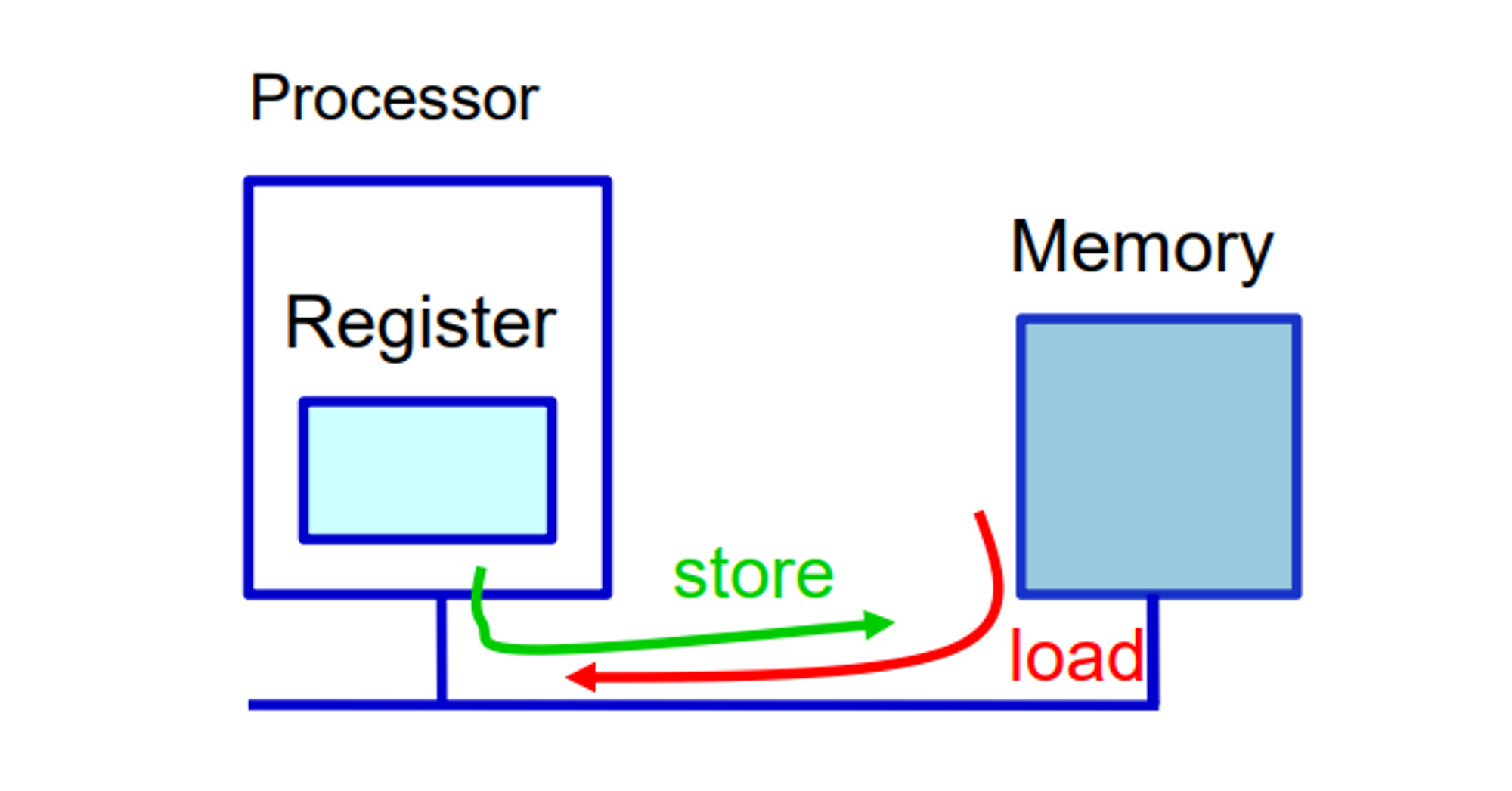
RISC-V에서 arithmetic operations(산술적 연산)은 오직 레지스터에서 작동하므로 RISC-V는 반드시 메모리와 레지스터 사이를 전송하는 instruction이 있어야 합니다.
- Load 명령어는 Memory → Register를 지원하고
- Store 명령어는 결괏값을 Register → Memory로 저장합니다.
이 Load와 Store 명령어를 Data transfer instructions라고 합니다.
→ 레지스터와 메모리사이를 전송하기 위한 instructions
Memory Addressing
메모리에 접근하기 위해 Instruction은 반드시 memory address를 지원해야 합니다.
- 메모리는 주소값이 index역할을 하는 큰 1차원 배열입니다.
→ 이때 주소는 0부터 시작을 합니다.

→ 예를 들어 위 자료에서는 3번째 data element의 주소가 2이므로
[2]= 10이 됩니다.
- 8-bit짜리 byte들은(bytes) 많은 프로그램에서 유용합니다.
→ 사실상 모든 architectures들이 개별 바이트를 처리함.
- word의 byte address는 word안에 포함된 4개의 bytes 중 하나의 주소와 일치합니다.(????)
→(아마 word는 32bit인데 byte는 8비트니까 one of the 4 bytes라고 기술한 거 같음)
- 순차적인 words의 주소들은 4씩 다르다.
Endian
Risc-V는 Little Endian방식이다.
LSB(Least significant byte)는 word의 가장 작은 주소값에 있다.
Little Endian vs Big Endian
Big-Endian : 데이터의 **MSB(most significant byte)**가 가장 낮은 주소값에 할당됩니다.
Little-Endian : 데이터의 LSB(Least significant byte)가 가장 낮은 주소값에 할당됩니다.
ex1)

ex2)
4-byte 상수 0x01234567을 저장할 때,
- Big endian이라면 0x100: 01, 0x101: 23, 0x102: 45, 0x103: 67 이렇게 저장된다.
- Little endian이라면, 0x100: 67, 0x101: 45, 0x102: 23, 0x103: 01 이렇게 저장된다
Memory Operand Example
예를 들어, 아래 C언어 식을 컴파일 한다고 합시다.
A[12] = h + A[8]:
h는 register x21에 있고, A의 base address는 x22에 있다고 가정합니다.
ld x9 , 32(x22) //Temporary reg x9 gets A[8]
add x9 , x21 , x9 //Temporary reg x9 gets h + A[8]
sw x9 , 48(x22) //Stores h + A[8] back into A[12]
여기서 32와 48의 의미는 index 8은 32(4*8)이며
48은 48(12*4)입니다.
- A [8] 값을 x9 register에 load 합니다.
- 그리고 x21에 있는 h값과 x9에 있는 A [8] 값을 더해 다시 x9 register에 저장합니다.
- 그다음 x9에 있는 값을 A [12]에 저장합니다.
자료들

