Procedure calls
procedures는 프로그래머가 한 번에 작업의 한 부분만 집중하게 해 줍니다.
procedure는 엄연하게 함수와는 다르지만 여기선 같다고 생각해 주시면 될 것 같습니다.

위의 c언어 코드를 아래로 나타낼 수 있습니다.
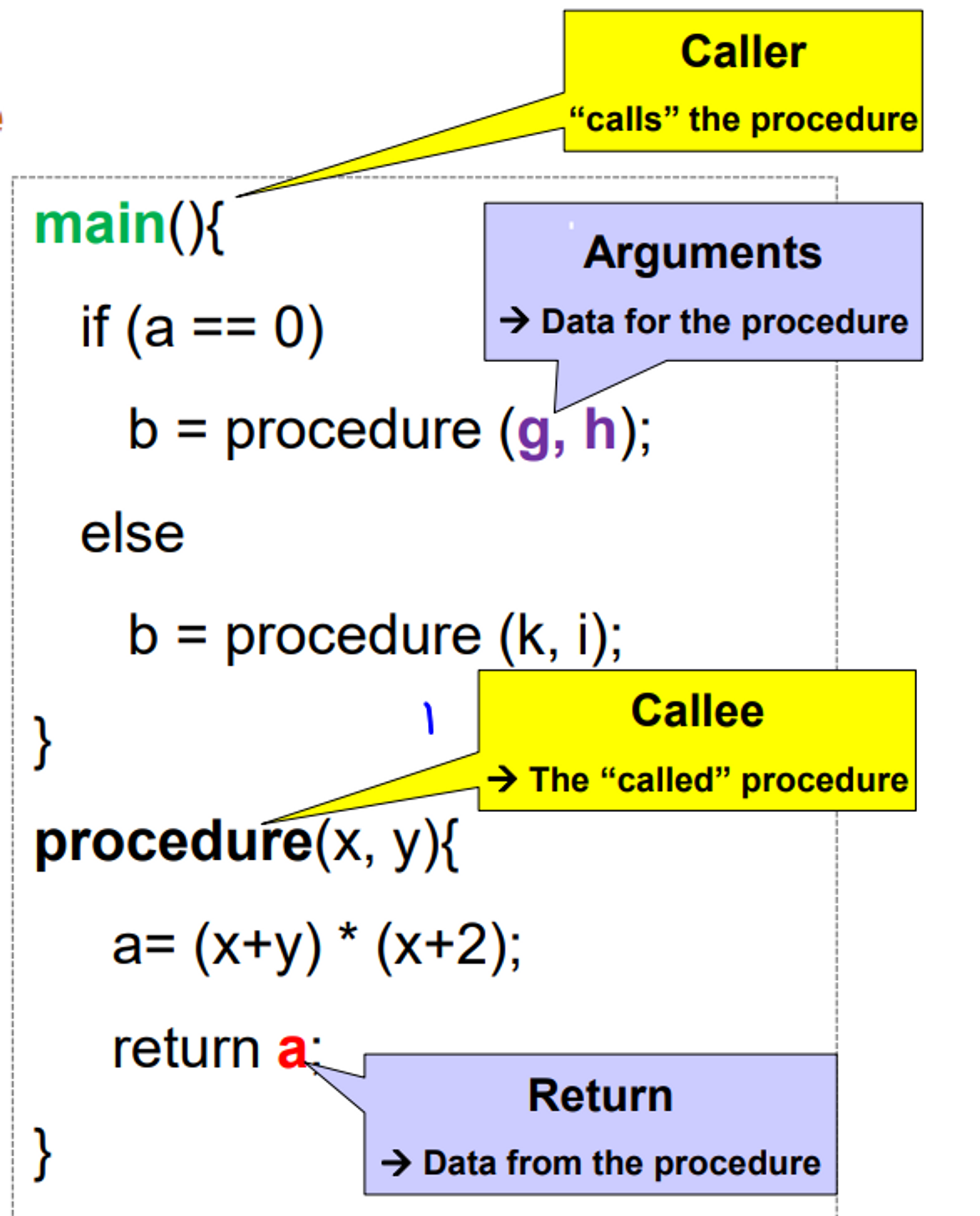
추가 예시)
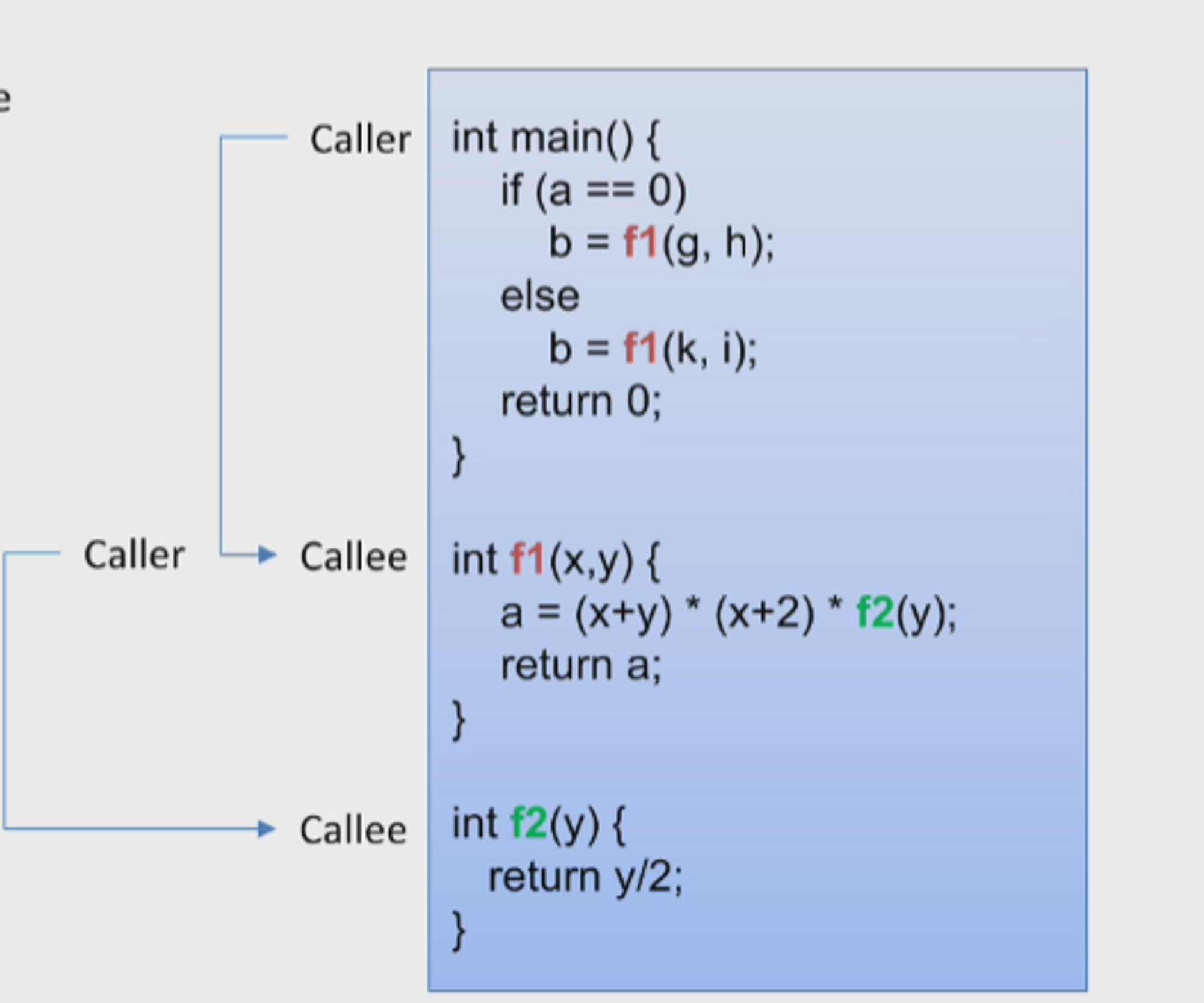
- caller : procedure을 호출합니다.
- callee : procedure입니다.
- caller는 callee에게 argument(실인자)를 줍니다.
- callee는 caller에게 결괏값을 return 해줍니다.
즉 추가 예시에서 f1 procedure는 caller이자 callee인 거죠.
Procedure Execution
프로그램은 procedure의 실행에서 6가지 스텝을 따라야 합니다.
- procedure가 접근할 수 있는 장소에 parameter들을 배치합니다.
- control을 procedure로 옮깁니다. (control은 현재 실행되는 코드 지점)
- procedure에게 필요한 저장공간을 확보합니다.
- 주어진 일을 수행합니다.
- calling 프로그램이 접근할 수 있는 곳에 결괏값을 배치합니다.
- control을 procedure가 호출된 장소로 반환합니다.
Program Counter(Pc)
현재 실행되고 있는 instruction의 주소를 담아두는 레지스터입니다.
원래 PC(Program Counter)는 instruction을 순서대로 실행하기 위해서 한 명령이 끝나면 4씩 증가합니다. (각 명령 크기가 4 byte임)

RISC-V는 procedure calling을 위하여 9개의 레지스터를 할당하였습니다.
- x10~ x17 : 8개의 parameter(매개변수)를 위한 레지스터입니다. 여기서 parameter를 넘겨주거나 결괏값을 return 받습니다.
→ x10 , x11 은 결괏값을 두는 데 사용합니다. (i.e., return value)
- x1 : 돌아가야 할 원래 위치의 주소값을 두는 레지스터입니다. (PC 저장)

RISC-V는 procedure을 위한 instruction을 제공합니다.
두 번째로 Unconditional Branch가 있습니다.
여기에는 jal과 jalr이 있는데
- jal (Jump-and-link instruction)
jal 인스트럭션은 address로 branch 함과 동시에 다음 instruction의 주소(PC+4)를 rd(destination register)에 저장합니다.
jal x1, ProcedureAddress //jump to ProcedureAddress and write return address to x1jal함수를
jal x0, Label처럼 이용하여 return address를 저장하지 않고 branch 하는 법도 있습니다!

RISC - V는 indirect jump를 사용하여 프로시저로부터의 return을 지원합니다.
- jalr(Jump-and-link register)
jalr x0, 0(x1)
- register x1에 저장된 주소로 branch(분기)합니다.
- x0을 rd(destination register)로 사용합니다.
→ 이것은 return address를 버리는 용도입니다.

Using More Registers
- 만약 procedure(함수)가 arguments를 8개 이상 사용하거나 return value를 2개 이상 사용한다면 더 많은 argument와 return value를 위한 Memory가 필요할 것입니다.
레지스터들의 수는 정해져 있습니다. 그러므로 procedure를 실행하기 위해서 우린 caller’s local values들을 register에서 memory로 옮겨야 합니다.
- Register spilling: 레지스터에 있는 어떤 값을 메모리에 저장하는 것.
- spilling register들을 위한 이상적인 자료구조는 바로 Stack입니다.
- Load와 Store Instructions이 메모리 안에 있는 stack에 접근하곤 합니다.
- stack에는 Push와 Pop 명령어들이 명시되어 있지 않습니다.
- 그러므로 Load Instruction을 pop, Store Instruction을 push라고 생각하면 될 겁니다.
- Load와 Store Instructions이 메모리 안에 있는 stack에 접근하곤 합니다.
- Stacks들은 high address → low address로 갑니다.
- RISC-V에서 stack pointer는 x2 register입니다. (sp라고 합니다.)
- sp는 word단위로 조절됩니다.
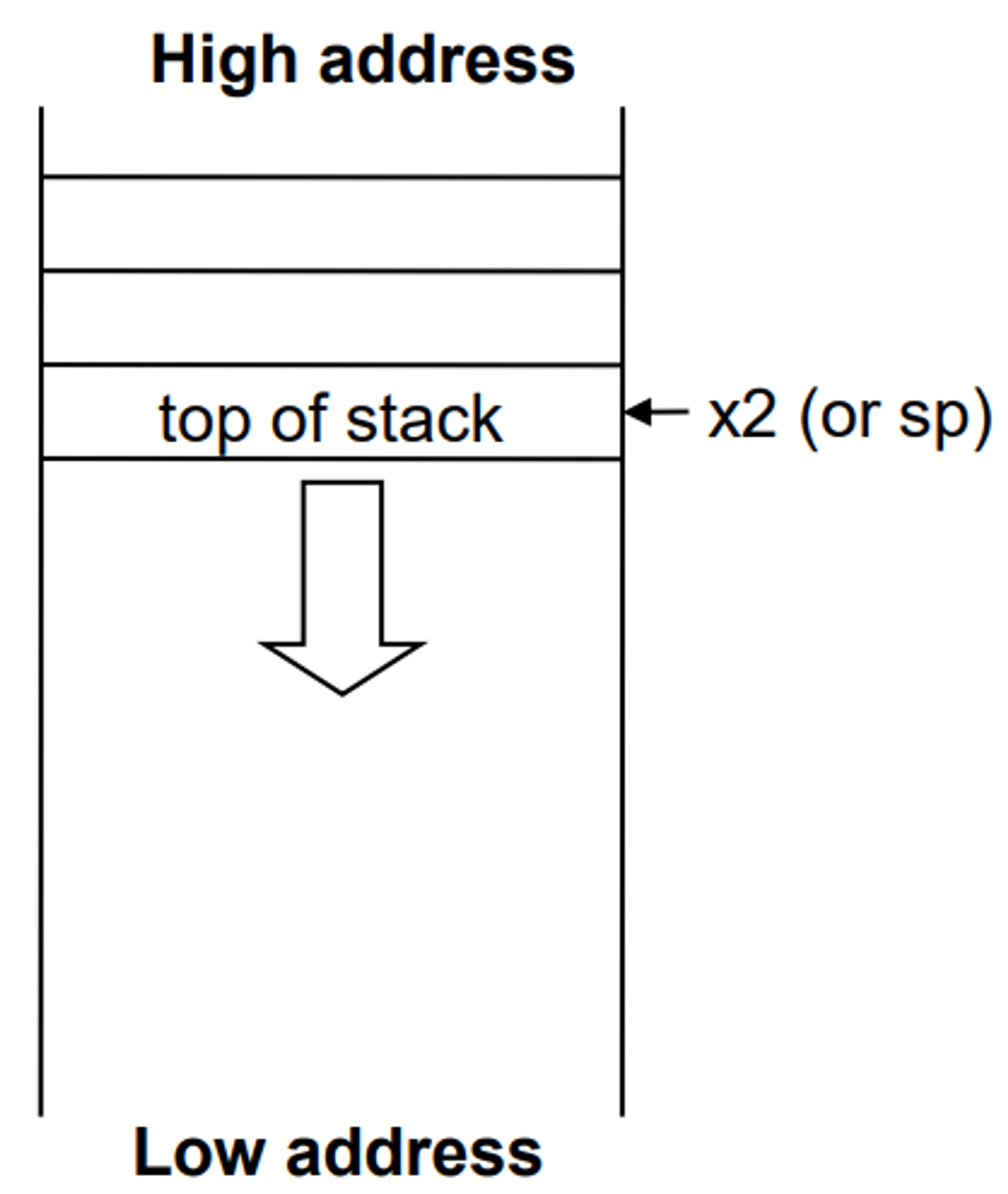
예를 들어 sp에 -4를 한다면 그건 4Byte의 공간을 push(store) 한 것이고 sp에 +4를 한다면 4Byte의 공간을 pop(load) 한 것이죠.
Compiling a Leaf Procedure

leaf_example 함수에서 사용하는 register는 총 3개입니다. 따라서 sp를 -12 해서 공간을 확보합니다.(x5, x6, x20을 위한 공간)
하지만 x5 , x6 , x20 이 caller에서 저장한 값이 들어가 있었을 수 있겠죠?
그러므로 이후엔 return 하기 전에 값을 복구해 줌으로써 caller의 local value를 돌려줍니다.
http://www.tcpschool.com/c/c_memory_stackframe
위 사이트를 참고하시면 스택 프레임에 관한 이해가 쉬울 것 같습니다.
Register Saving Convention
- 사용된 적 없는 값의 레지스터를 저장하고 복구하는 불필요한 일을 피하기 위하여 RISC-V에서는 19개의 register들을 2개의 그룹으로 나누었습니다.
- Caller saved registers
- x5 ~ x7 그리고 x28 ~ x31 : procedure 호출 때 callee에 의해 저장되지 않습니다.
- Caller는 호출 이전에 스택에 값을 저장해야 합니다.
- 이 레지스터들의 내용들은 함수 호출의 결과로 수정될 수 있습니다.
- Callee saved registers
- x8 ~ x9 그리고 x18 ~ x27 : 함수 호출 때, 반드시 저장되는 레지스터입니다.
- Callee는 값이 사용되기 전에 스택에 임시 값을 저장합니다.
- Callee는 caller에게 값을 돌려주기 전에 다시 복구합니다. (값이 저장이 돼있단 뜻)
- 이 레지스터에 있는 값들은 함수 호출을 통해서도 유지됩니다.
- 그러므로 사실상 위에 있는 Leaf Procedure의 예시에서 sw/lw x5, x6은 필요하진 않지만 x20의 sw/lw는 필요한 작업입니다.
Allocating Space for New Data on the Stack
- 스택은 함수의 호출과 관계되는 지역변수와 매개변수뿐 아니라 배열이나 구조체등을 저장하기 위해 사용됩니다.
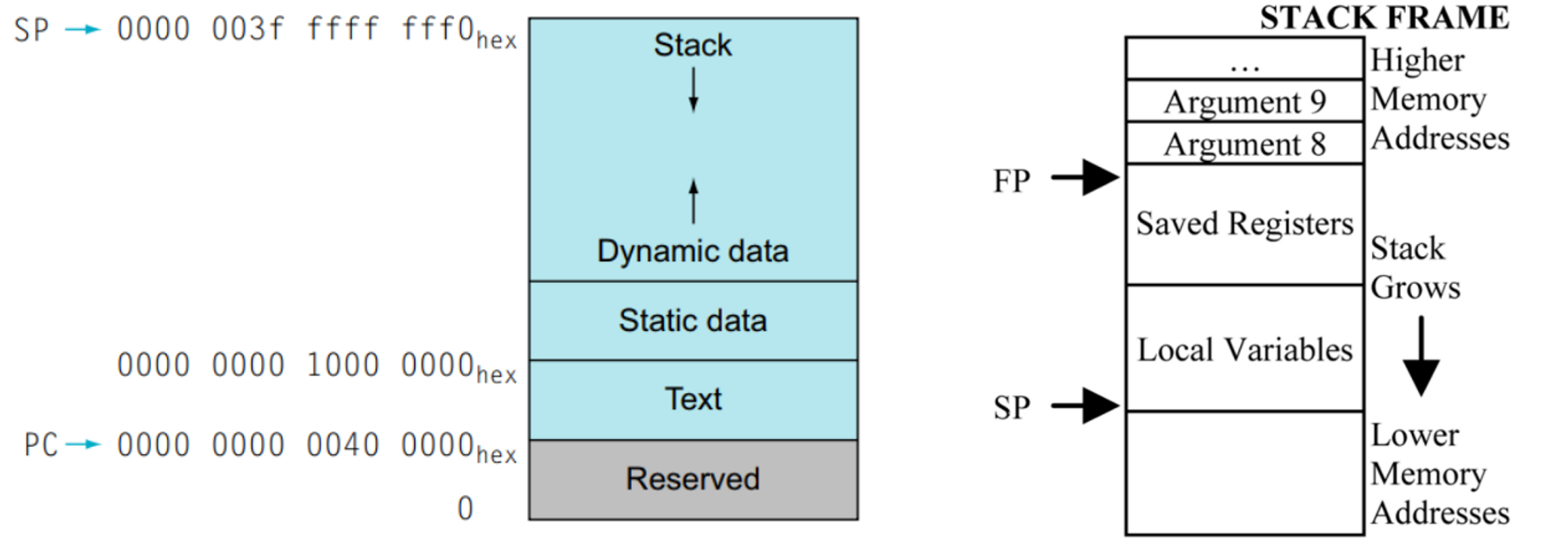
- 스택에서 레지스터를 저장하고 지역 변수들을 포함하는 부분을 procedure frame 또는 activation record라고 부릅니다.
- Frame pointer(fp, or x8)은 frame에서 첫 번째 word를 가리킵니다.
- stack pointer는 함수 진행 동안에 바뀔 수 있습니다.
- frame pointer는 로컬 메모리 참조를 위한 과정에서 안정적인 기본 베이스를 제공합니다. (아마 그래서 High address로 시작하는 듯.)

Allocating Space for New Data on the Heap
— RISC-V의 메모리 할당—
이 쪽은 꽤나 프로그래밍 기초 시간에 배운 메모리 구조와 정말 흡사하다고 생각합니다.
- Text : Code영역이라고도 부르며 프로그램의 코드가 저장되는 영역입니다.
- Static Data: 상수와 다른 정적 변수들이 차지하는 곳.
- Heap (Dynamic Data): 동적 할당 시 사용되는 메모리.
- e.g.) 연결 리스트, 트리 → C언어에서 malloc() / free()
- Stack: 지역 변수나 register가 저장되는 곳.
- Stack과 Heap은 같은 공간을 사용합니다. (사견이고 아닐 수도 있음!)
- 스택은 높은 번지수에서 낮은 번지수로, 힙 영역은 낮은 번지수에서 높은 번지수로 향하기 때문에 서로 충돌하기 전까지 메모리 사용 효율을 극대화할 수 있습니다.
Wide Immediate Operands
예를 들어, 3,998,976이란 숫자를 만들어본다고 가정합니다.
이 숫자를 2진수로 변환하면 아래와 같이 나옵니다.
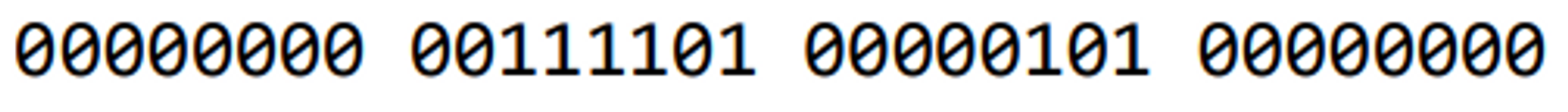
I-Type의 같은 경우 imm field는 12 bit밖에 표현되지 않습니다.
그렇다면 우리가 큰 수를 만들기 위해서는 계속 addi를 하는 방법뿐일까요?
아닙니다.
RISC-V에서는 lui(load upper immediate. U-Type)을 제공합니다.
lui는 opcode(7bit), rd(5bit)를 제외한 나머지 [12:31] bit를 immediate field로 사용합니다.
또 이 명령어는 immediate field에 위치하는 20bit를 상위 20bit에 배치시킵니다.
즉 rd register의 [31:12] bit에 위치시키는 거죠.
그리고 나머지 [0:11] bit를 0으로 채웁니다.
아래 예시를 보면서 이해하면 편할 것 같습니다.

처음에는 아래 instruction을 사용합니다.
lui x19, 976 //976 == 0000 0000 0011 1101 0000
이 과정이 지나면 x19 에는 00000000 00111101 00000000 00000000이 들어갑니다.
그다음
addi x19, x19, 1280 //1280 == 0000 0101 0000 0000
이 과정이 다 끝나면 x19 에는 3,998,976가 들어가게 됩니다.
Addressing in Branches
- RISC-V에서 branch instruction은 SB-TYPE입니다.
- 이러한 형식은 주소 -4096에서 4094까지 분기가 가능합니다. 하지만 무조건 짝수 숫자로만 분기 가능합니다!! (4023 같은 홀수는 불가능)

- jump-and-link instruction (jal)는 UJ-TYPE입니다.
- immediate field가 20bit입니다.

PC-relative Addressing
- 프로그램의 번지수가 20-bit에 맞혀져있어야 한다면, 프로그램의 번지수는 전부 2^20보다 적어야 합니다.
- 하지만 이건 현재 사회에서는 터무니없이 적은 수입니다.
- branch 같은 경우에는 +-2^10, jump 같은 경우에는 +- 2^18으로 이동이 가능합니다.
- jal은 UJ-TYPE으로 opcode, register를 제외한 나머지 20bit + 1bit 총 21bit로 움직입니다.
- bne는 SB-TYPE으로 immediate field의 12bit+1bit 총 13bit로 움직입니다.
- +1을 하는 이유는 위에 SB-TYPE과 UJ-TYPE을 보면 immediate field가 1부터 시작인 것을 볼 수 있습니다. 그렇기에 0번째 bit를 위해 +1을 하는것입니다.
왜 21bit인데 +- 2^18이고 13bit 가지고 +- 2^10밖에 못 가는지 궁금하실 수 있습니다.
일단 프로그램의 번지수는 word단위입니다.
1 word는 4byte로 구현되어 있죠.
한 word 내에서 정확한 위치를 구현하기 위해 2bit를 제외하는 것입니다. (2bit만 있으면 숫자 4개를 표현할 수 있으므로 1 word 내에서 정확한 위치를 찾는 것이 가능)
또한 branch나 jump가 플러스만 되는 것이 아니고 음수 또한 표현해야 하기 때문에 21bit로 +-2^18만 갈 수 있는 것입니다.
'컴퓨터구조' 카테고리의 다른 글
| [컴퓨터 구조]제 4장. Pipeline(2) (0) | 2023.04.09 |
|---|---|
| [컴퓨터 구조]제 4장. Pipeline (1) | 2023.04.08 |
| [컴퓨터 구조]제 2장. 명령어(Instruction) : 컴퓨터의 언어 (2) (1) | 2023.04.08 |
| [컴퓨터 구조]제 2장. 명령어(Instruction) : 컴퓨터의 언어 (4) | 2023.03.17 |
| [컴퓨터 구조] 제 1장. 컴퓨터 추상화 및 기술 (2) | 2023.03.16 |